1.网络爬虫又称网络蜘蛛、网络机器人是一种按照一定的规则,自动抓取万维网信息的程序或脚本
2.搜索引擎就是通用网络爬虫,如:google、百度(通用爬虫) 通用爬虫具有一定的局限性
3.网络爬虫类型:通用网络爬虫、聚集网络爬虫、分布式网络爬
4.爬虫主要步骤:
1.对爬取目标的 url 定义
2.对网页数据分析与协议获取对应 HTML
3.对页面进行提取 HTML 页面有价值的数据
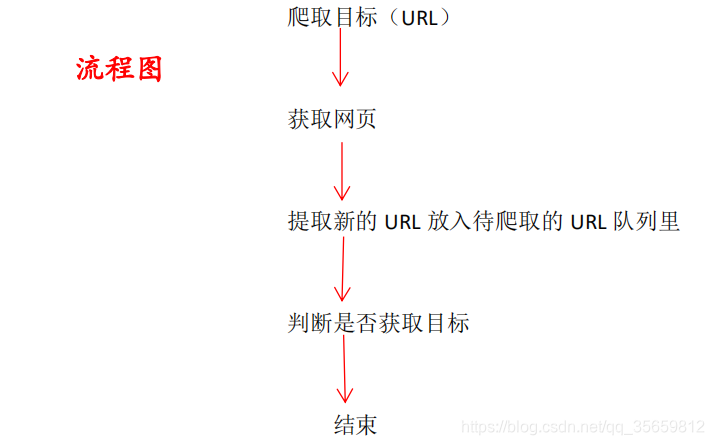
- 通用爬虫需要遵守一定规则(nofollow 协议或 Robots 协议),全称是网络爬虫排除标准
- 通用爬虫只能抓取 HTML、PDF、word、wps、XLP、PPT、TXflash、音频、脚本程序
- HTTP 协议(Hyper Text Transfer Protocl,超文本传输协议)是面的规则
- HTTPS 协议(Hypertext Transfer Protocl oVer Secure Socket Laye层(安全套接层)主要用于安全传输协议,在网络传输层进行加密
- HTTP 的端口号:80
- HTTPS 的端口号:443
- HTTP 请求与响应:浏览器发送请求等待服务器响应并返回数流程图 浏览器 发送请求数据 响应并返回数据

- 统一资源定位符 URL:如 http://www.baidu.com:8080/a

11.客户端 HTTP 请求:
- 浏览器发送一个 HTTP 请求到服务器
- 请求格式: 请求行、请求头、空行.请求数据
- GET: http:// www.baidu.com/HTTP/1.1
- Host::www.baidu.com
- User-Aget: Mozilla/chrome
- Cookie:
12.HTTP 请求主要分为 get 和 postGet 请求:
- Get请求:是从服务器上获取页面信息
- Post 请求:是向服务器提交数据并获取页面信息
- Get 请求参数都显示在 URL 上,服务器根据请求 URL 的参数产生响的一部分
- Post 请求参数在请求体中,消息长度没有限制而且隐式方式进行在 URL 中,而是在请求体中因此 Get 请求方式不安全,而 Post 请求方式相对来说比较安全
13.请求报头
- Host(主机和端口号)
- UPgrade-lnsecure-Reuqusts(升级为 HTTPS 请求)
- User-agent(浏览器名称)
- Accept(传输文件类型)
- Referer(页面跳转来源)
- Accept-Encoding(文件编解码格式)
- Accept-Language(语言类型)
- Accept-charset(字符编码)
- CookieContent-Type(Post 数据类型)
- 服务端 HTTP 响应
14.响应报头
- Cache-Control:must-revalidate,no-cache,Private
- Connection:Keep-alive
- Content-Encoding:gzip
- Content-Type:text/html;charset = utf-8
- Date:sun,21 sep 2017.01:06.21 GMT
服务器端发送资源时的时间,不同时区在相互请求资源时间混乱,http 协议中发送时间都
是 GMT - Server : Tengine/1.4.6
服务器和相对应的版本,只是告诉浏览器服务器的信息 - Transfer-Encoding:chunked
- 响应状态码:
- 200:访问成功正常
- 404:访问失败,没有找到请求信息
- 500:服务器端出现错误,请求未完成


